
En VCF 9.0, le modèle VPC a démocratisé le réseau pour les équipes applicatives — mais la frontière avec le fabric physique restait artisanale, et le scale du data plane VPC montrait ses limites (pas de L4 LB natif, pas d’IPSec, dérive de config silencieuse). VCF 9.1 ne réécrit pas NSX : il colmate méthodiquement les jointures qui faisaient mal en production.
Cet article décortique les nouveautés networking & scale de VCF 9.1 du point de vue de l’architecte réseau : ce qui change concrètement entre 9.0 et 9.1, ce que ça implique pour ta topologie, et les pièges de migration que les release notes ne mettent pas en gras.
Série « Nouveautés VCF 9.1 » — 2/4
Mini-série sur les nouveautés de VMware Cloud Foundation 9.1 :
- Efficience d’infrastructure & TCO
- Networking & scale (cet article)
- Kubernetes & self-service
- Sécurité & résilience
Crédits visuels
Captures © Broadcom, reprises du blog officiel VCF (liens en fin d’article). Synthèse et analyse personnelles.
EVPN-VXLAN : interopérabilité avec le fabric physique
Le sujet le plus structurant de la release. Jusqu’en 9.0, faire dialoguer un VPC NSX avec le fabric physique du datacenter relevait du sur-mesure : routes statiques, BGP point à point, redistribution manuelle entre le Tier-0 et les switches de spine. Chaque tenant qui devait toucher un réseau physique (stockage NAS, mainframe, segment legacy non-overlay) générait un ticket réseau et une exception d’architecture.
VCF 9.1 standardise cette intégration via EVPN-VXLAN. Le fabric physique parle déjà EVPN sur quasiment tous les datacenters modernes (Cisco ACI/NX-OS, Arista EOS, Juniper) ; NSX rejoint désormais ce plan de contrôle au lieu de l’inventer en parallèle. Concrètement, un VNI L3 EVPN est exposé côté NSX, les préfixes des VPC et des workloads VCF y sont annoncés via BGP-EVPN (famille d’adresses L2VPN/EVPN, type-5 routes pour le L3), et le fabric apprend nativement les subnets VPC sans redistribution artisanale.
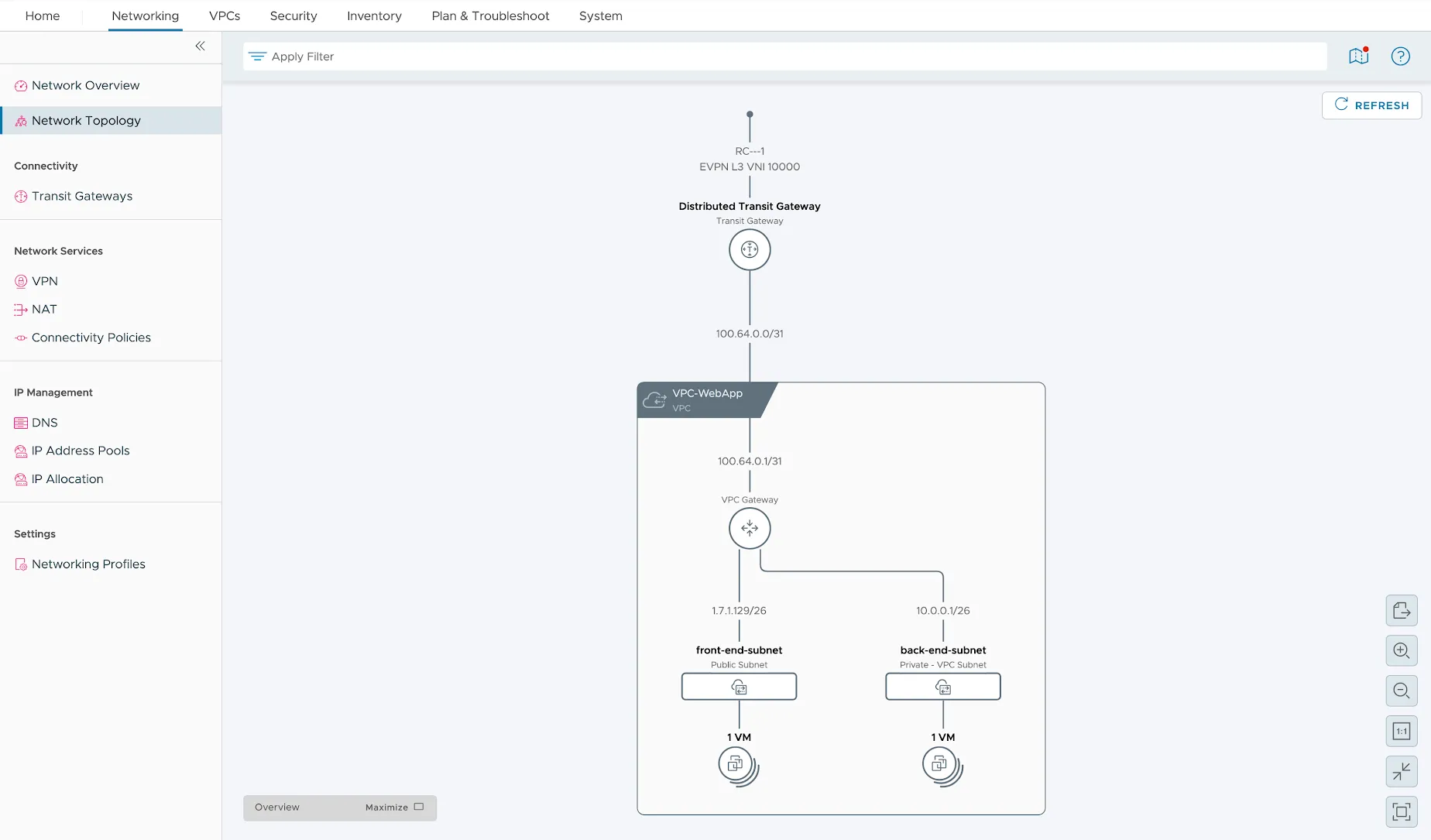
Source : Broadcom — VCF Blog
La capture de l’UI Network Topology de NSX rend la chose lisible. On y lit, de haut en bas : un EVPN L3 VNI 10000 qui matérialise le pont de routage avec le fabric physique ; un Distributed Transit Gateway qui agrège les VPC et porte la connectivité nord-sud distribuée (le routage est exécuté au plus près du workload, pas centralisé sur une paire d’Edge) ; et en dessous le VPC VPC-WebApp qui expose deux subnets — un front-end-subnet public (face Internet / DMZ) et un back-end-subnet privé (tier applicatif et données, jamais routé hors du VPC sans politique explicite). C’est le pattern de référence trois tiers, mais ici tout est déclaratif et le pont EVPN remplace les routes statiques.
| Aspect | VCF 9.0 | VCF 9.1 |
|---|---|---|
| Intégration fabric physique | Routes statiques / BGP point à point manuels | EVPN-VXLAN standardisé (type-5 routes) |
| Annonce des subnets VPC au fabric | Redistribution artisanale par tenant | Native via BGP-EVPN |
| Routage nord-sud des VPC | Centralisé sur paire d’Edge | Distributed Transit Gateway (au plus près du workload) |
| Onboarding d’un nouveau VPC routé | Ticket réseau + exception d’archi | Politique déclarative |
Note d’architecte. L’EVPN-VXLAN ne se décide pas côté NSX seul : c’est une discussion avec l’équipe fabric (numéros d’AS, route targets, VNI mapping, anti-spoofing sur les type-5). Aligne le plan de VNI dès la phase de design — un VNI mal cloisonné entre tenants est un risque de fuite L3 qui ne se voit pas avant l’audit.
VPC Load Balancer L4 & IPSec VPN
Les deux trous fonctionnels du VPC 9.0 qui forçaient à « casser » le modèle et à revenir à du NSX direct.
Load Balancer L4. Le VPC supporte désormais l’équilibrage de charge L4 (TCP/UDP) nativement, matérialisé par une solution portée sur une Virtual Networking Appliance (VNA) — une appliance de data plane dédiée au VPC, distincte des Service Engines NSX ALB historiques. L’intérêt : un développeur expose un service L4 (base de données, broker de messages, endpoint gRPC) sans demander une VirtualService Avi à l’équipe réseau. Le LB vit dans le périmètre du VPC, suit son lifecycle déclaratif, et reste isolé des autres tenants.
IPSec VPN. Le VPC supporte maintenant l’IPSec VPN site-à-site, en s’appuyant sur la connectivité externe centralisée. Un VPC peut donc établir un tunnel chiffré vers un site distant (cloud public, datacenter partenaire, on-premise legacy) sans passer par un Tier-0 partagé géré hors du modèle VPC. C’est la fonctionnalité qui rend le VPC viable pour des cas hybrides réels, pas seulement pour de l’isolation intra-datacenter.
| Capacité | VCF 9.0 (VPC) | VCF 9.1 (VPC) |
|---|---|---|
| Load Balancing | L7 via NSX ALB hors modèle VPC | L4 natif sur VNA, dans le VPC |
| VPN site-à-site | Non — retour au NSX direct | IPSec VPN via connectivité externe centralisée |
| Périmètre de gestion | Mixte VPC + tickets réseau | Déclaratif, dans le lifecycle du VPC |
Note de migration. Si tu avais contourné l’absence de L4/VPN en sortant du VPC (Tier-1 dédié, Avi hors VPC), 9.1 ouvre un chemin de re-convergence vers le modèle VPC. Ne migre pas pour migrer : la valeur se révèle quand le nombre de tenants exposant du L4/VPN dépasse le seuil où la gestion par tickets devient le goulot. Tu retrouveras la logique de l’article 1 sur le TCO — moins de tickets réseau, c’est aussi du TCO opérationnel.
SDDC Manager : synchronisation de configuration
Le scénario classique du brownfield : un opérateur applique un changement réseau directement dans vCenter ou NSX Manager (urgence, habitude, contournement d’un workflow trop lent) et la base SDDC Manager ne le sait pas. Au prochain remédiation ou upgrade, SDDC Manager réapplique sa vision « source of truth » et écrase la modification — ou pire, refuse de progresser sur une dérive qu’il ne sait pas réconcilier.
VCF 9.1 introduit la synchronisation de configuration : les changements de configuration réseau effectués directement dans vCenter ou NSX Manager remontent désormais dans la base de données SDDC Manager. Le drift est réconcilié au lieu d’être ignoré puis écrasé. SDDC Manager passe d’un modèle « j’impose ma vérité » à un modèle « je réconcilie l’état réel ».
| Comportement | VCF 9.0 | VCF 9.1 |
|---|---|---|
| Changement réseau direct vCenter/NSX | Invisible pour SDDC Manager | Remonté dans la base SDDC Manager |
| Dérive de config | Écrasée au prochain remédiation | Réconciliée (drift reconciliation) |
| Brownfield avec ops manuelles | Source de blocage upgrade | Toléré et synchronisé |
Note d’architecte. Cette feature ne dispense pas de discipline : la synchronisation réconcilie, elle ne valide pas. Un changement « sauvage » techniquement correct mais hors gouvernance sera synchronisé et donc pérennisé. Garde une revue de drift périodique dans VCF Operations — la synchro réduit le risque de blocage, pas le besoin de traçabilité.
Import d’edges NSX bare-metal & certificats non-disruptifs
Deux nouveautés qui visent les déploiements brownfield et l’industrialisation.
Import d’edges bare-metal. Les déploiements NSX existants hors VCF, équipés de nœuds Edge bare-metal (pour le throughput nord-sud élevé, le déchargement crypto, ou les contraintes de latence des Edge VM), peuvent désormais être importés dans VCF. Auparavant, un Edge bare-metal était un motif de non-éligibilité à la convergence ; il fallait reconstruire en Edge VM ou rester hors VCF. En 9.1, l’investissement matériel Edge est préservé lors de l’adoption de VCF.
Certificats non-disruptifs. Les composants consommateurs de NSX adoptent l’architecture de certificats non-disruptifs standardisée. La rotation des certificats (renouvellement, ré-émission après compromission, rotation de conformité) ne nécessite plus de fenêtre de rupture du data plane. Pour une plateforme qui consomme NSX sous SLA, c’est la différence entre une rotation de certificat planifiée hors heures et une rotation transparente.
| Aspect | VCF 9.0 | VCF 9.1 |
|---|---|---|
| Edge bare-metal existant | Non importable — reconstruire en Edge VM | Importable dans VCF |
| Rotation de certificat NSX | Fenêtre de rupture possible | Non-disruptive, architecture standardisée |
| Éligibilité brownfield NSX | Restreinte | Élargie (bare-metal inclus) |
Note de migration. L’import d’Edge bare-metal a des contraintes (versions NSX supportées, topologie de cluster Edge, prérequis sur le fabric). Ce n’est pas un lift-and-shift aveugle : audite la version NSX source et la conformité de la topologie Edge avant de t’engager sur un planning de convergence.
Réseaux secondaires multi-NIC pour les pods VKS
Côté Kubernetes, VCF 9.1 introduit les réseaux secondaires multi-NIC pour les pods VKS. Par défaut, un pod a une seule interface (eth0) sur le réseau primaire du cluster. Certaines charges réseau-intensives ou réglementées ont besoin d’une seconde interface, sur un réseau séparé, avec ses propres règles.
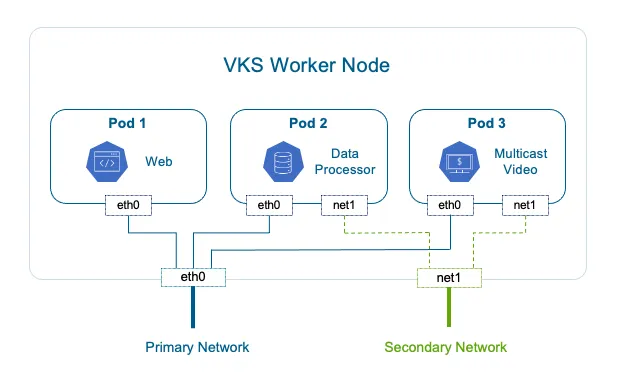
Source : Broadcom — VCF Blog
Le schéma illustre un node worker VKS portant trois pods. Pod1 (Web) et Pod2 (Data Processor) n’utilisent que eth0 sur le réseau primaire — le cas standard, suffisant pour 90 % des workloads. Pod3 (Multicast Video) porte en plus une interface net1 rattachée à un réseau secondaire. Les cas d’usage typiques : trafic multicast (vidéo, market data, découverte de services legacy) qui ne traverse pas l’overlay primaire ; séparation plan de données / plan de contrôle pour des VNF/CNF télécom ; isolation réglementaire d’un flux (paiement, santé) sur un segment dédié avec son propre firewall ; ou un plan de stockage haute performance distinct du trafic applicatif.
| Capacité | VCF 9.0 | VCF 9.1 |
|---|---|---|
| Interfaces par pod VKS | 1 (eth0, réseau primaire) | Multi-NIC (eth0 + net1/N réseaux secondaires) |
| Multicast / plan de données séparé | Non supporté nativement | Réseau secondaire dédié |
| Isolation réglementaire d’un flux pod | Contournement (NetworkPolicy / node pool) | Interface secondaire sur segment isolé |
Note d’architecte. Le multi-NIC déplace la complexité, il ne la supprime pas : chaque réseau secondaire est un plan d’adressage à gérer, une matrice de firewall supplémentaire, et un point de diagnostic en plus. Réserve-le aux workloads qui le justifient réellement (multicast, télécom, contrainte réglementaire) — ne le généralise pas par confort.
Observabilité & planification réseau dans VCF Operations
Le scale réseau ne se gère pas à vue. VCF 9.1 enrichit VCF Operations de deux capacités directement utiles à l’architecte.
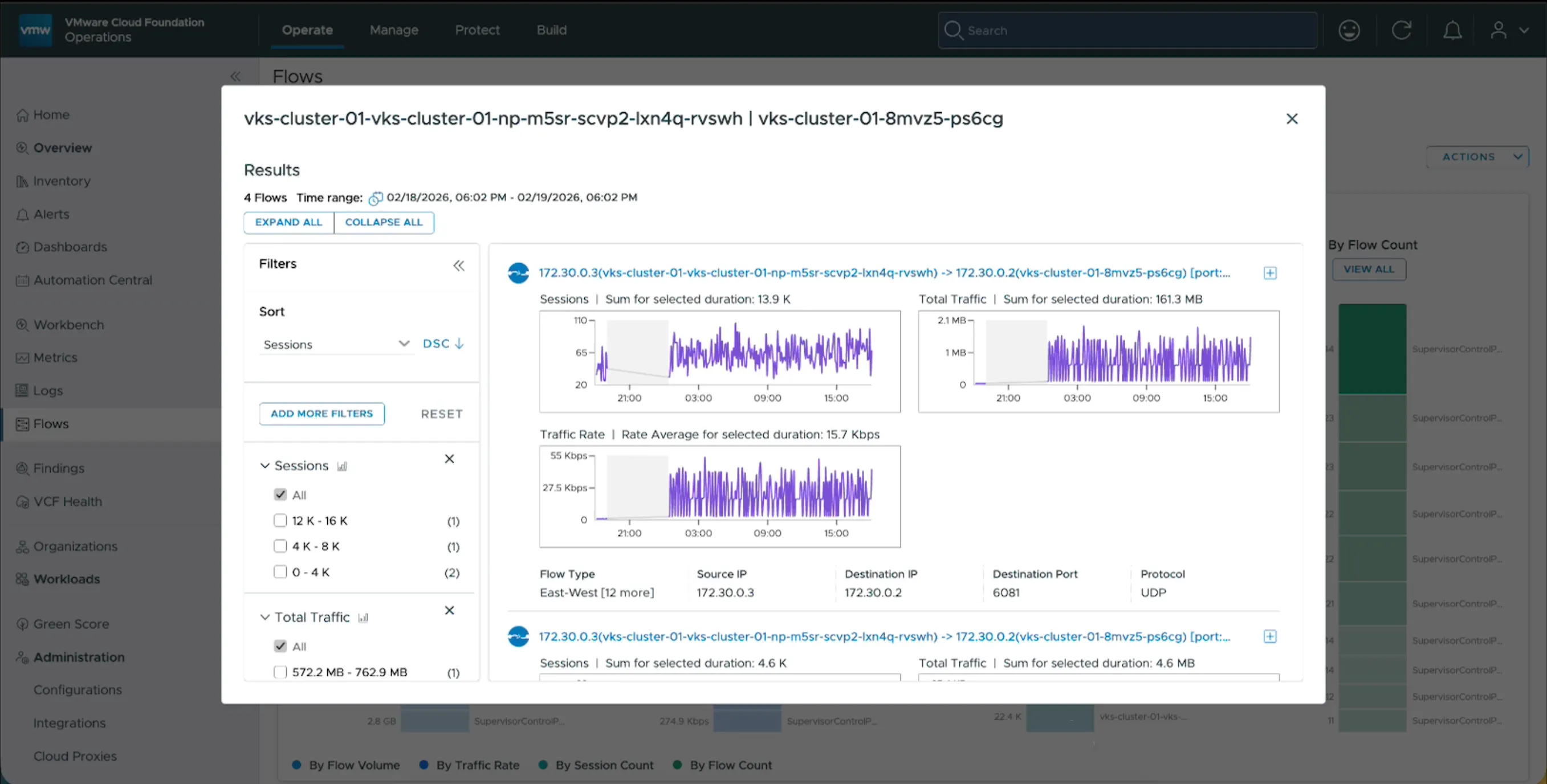
Source : Broadcom — VCF Blog
La vue Flows réseau pour clusters VKS expose le trafic au niveau des clusters Kubernetes : nombre de sessions, volume de trafic, et types de flux (est-ouest intra-cluster, nord-sud, inter-namespace). C’est ce qui manquait pour dimensionner un VPC ou un node pool sans extrapoler : on observe le trafic réel par cluster au lieu de provisionner « large par sécurité ».
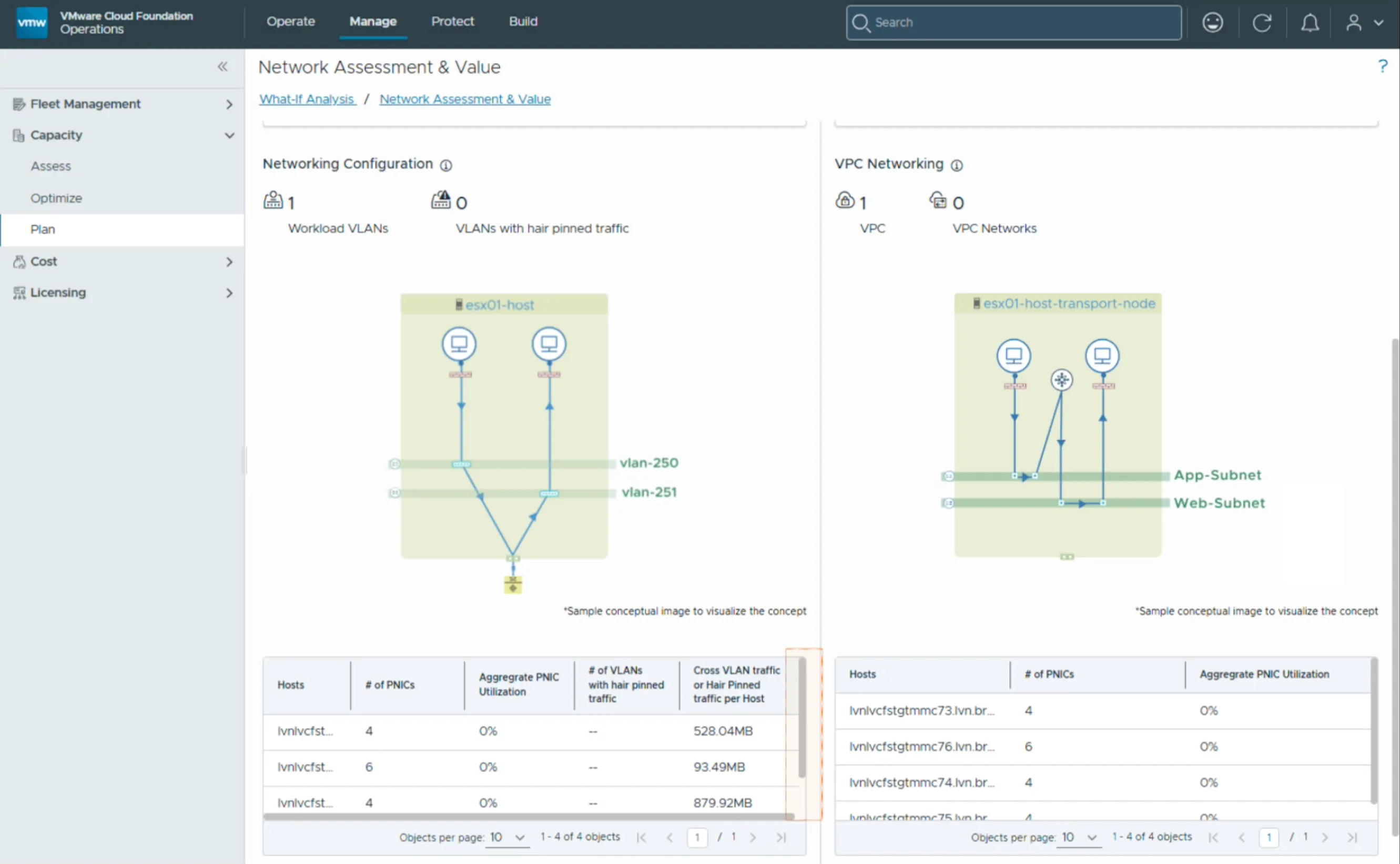
Source : Broadcom — VCF Blog
La vue Network Assessment & Value monte d’un cran : inventaire des VLANs, détection du trafic hair-pinné (flux qui sort puis revient inutilement, signe d’une topologie ou d’un placement à corriger), cartographie du networking VPC, et utilisation des PNIC physiques. C’est l’outil de planification de capacité réseau : il transforme « on pense que la NIC sature » en « voici les PNIC à 85 %, voici les flux hair-pinnés à éliminer, voici la marge avant le prochain VPC ».
| Capacité d’observabilité | VCF 9.0 | VCF 9.1 |
|---|---|---|
| Visibilité flux par cluster VKS | Limitée / externe | Native (sessions, trafic, types de flux) |
| Détection trafic hair-pinné | Manuelle | Network Assessment & Value |
| Planification capacité PNIC / VPC | Estimation | Mesurée et cartographiée |
Lien avec le scale. Toutes les nouveautés de cette release (EVPN, VPC L4/VPN, multi-NIC) ajoutent des plans de trafic. Sans cette observabilité, on les empile à l’aveugle. La discipline 9.1 : chaque nouveau VPC ou réseau secondaire se justifie par une mesure dans Network Assessment, pas par une intuition.
Pièges & points de vigilance
EVPN-VXLAN : MTU et alignement fabric
VPC Load Balancer L4 : sizing de la VNA
IPSec VPN : prérequis de connectivité externe centralisée
Synchronisation SDDC Manager : réconcilie mais ne valide pas
Import d'Edge bare-metal : contraintes de version et de topologie
Rotation de certificats : non-disruptif ne veut pas dire automatique
Conclusion
Jointures colmatées
EVPN-VXLAN standardise l’intégration au fabric ; VPC L4 + IPSec ferment les trous qui forçaient le retour au NSX direct.
Brownfield élargi
Sync SDDC Manager, import d’Edge bare-metal et certificats non-disruptifs rendent l’adoption VCF moins destructrice.
Scale mesuré
Multi-NIC VKS pour les workloads exigeants, et observabilité réseau VCF Operations pour piloter le scale par la donnée, pas l’intuition.
Prochaine étape. L’article suivant traite du Kubernetes & self-service en VCF 9.1 : ce que change le multi-NIC côté plateforme, le self-service VKS, et la gouvernance des clusters à l’échelle. Le réseau étant cadré, c’est le prochain grand chantier de mise en production.
Pour aller plus loin.
- Networking & scale VCF 9.1 — VCF Blog — l’annonce officielle et les captures de cet article
- Release Notes — Nouveautés NSX 9.1 — le détail NSX par fonctionnalité
- Release Notes — VCF 9.1 — release notes complètes VCF 9.1
- William Lam — walkthroughs et retours de lab de référence sur VCF
